
Effectiveness of XIPU AI in Assisting Reading Test Development
1. Introduction
Reading comprehension is a fundamental skill crucial for academic achievement. Extensive research has consistently shown a strong correlation between reading proficiency, as measured by standardized tests such as IELTS and TOEFL, and the academic performance of students from non-native English backgrounds (Oliver et al., 2012). As a result, reading holds a pivotal role in language assessments. However, creating reading assessments can be a time-consuming and challenging task for language teachers due to the high-stakes nature of these assessments and their multiple professional responsibilities.
The latest development of GenAI has led to concerns in designing assessments, but it also provides opportunities such as automatic scoring, immediate feedback, and task generation. Recognizing the widely acknowledged advantages of AI in text and question generation, language educators can leverage its power to improve the efficiency of reading test development, especially in the stages of text generation and item formulation. However, each of these stages requires careful attention to detail and a comprehensive understanding of both the subject matter and the language being assessed. Given that GenAI is not directly relevant to language teaching and learning, the extent of its reliability in test development warrants scrutiny. This article aims to reflect on the author’s collaboration experience with XIPU AI in developing reading tests with multiple-choice questions (MCQs), while also sharing insights into leveraging GenAI in developing tests based on language assessment principles introduced by Brown (2019). The implication drawn could be helpful in future formative and summative reading test development.
2. Generating reading texts
2.1 Authenticity
One of the critical components of assessing reading proficiency involves text generation. (Brown, 2019)emphasizes that “an authentic test contains language that is as natural as possible”. Despite the expedited and readily accessible nature of AI-generated content creation, it has faced criticism for generating content that is incoherent, inaccurate, detached, outdated, lacking in moral sensibilities, and unable to offer original insights (Elkhatat, 2023). These limitations hinder its ability to engage with audiences and evoke emotional, moral, and aspirational responses. While GenAI can imitate the style and structure of authentic texts, it may not fully capture the depth and intricacy of human-authored text. As test developers, we aim to uphold the principle of authenticity. Therefore, it is imperative to utilize content sourced from reputable and verified articles for their features of reliability, currency, creativity, personal connection, and originality.
2.2 Texts adaptation
The above-mentioned limitations of AI-generated texts, however, do not preclude teachers from leveraging AI assistance in the development of reading tests. AI possesses the capability to assist us in tailoring texts to match the language proficiency levels, such as CEFR levels, of targeted students by adjusting readability. This adjustment involves simplifying complex phrasing and vocabulary, breaking down lengthy sentences, and avoiding technical jargon or excessively sophisticated language, all while preserving the core message of the passage. Nevertheless, it remains crucial to validate AI-generated reading texts using supplementary tools such as Flesch-Kincaid level, Coh-Metrix, or other text analyzers. Additionally, it is important to acknowledge that XIPU AI may not effectively expand or condense an entire article to meet a specified word count. Thus, it is advisable to manually adjust the length of texts to accommodate AI's limitations and optimize the preservation of the tone and style of the original passage.
3. Generating items
3.1 Validity
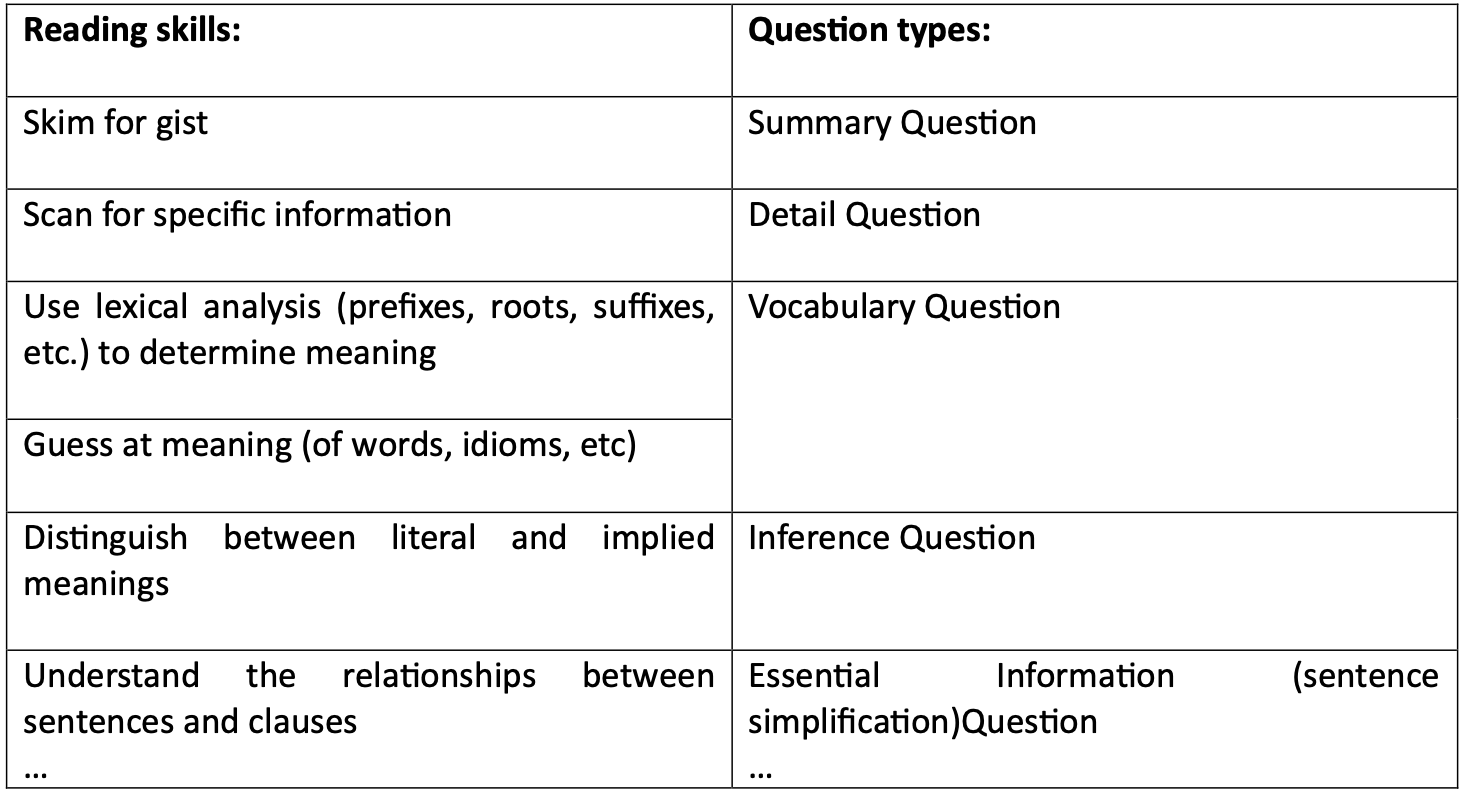
A valid reading test considers course content such as topics, learning objectives, reading constructs (skills required for readers to effectively manage the demands of the targeted language domain), and suitable difficulty levels (Brown, 2019). Despite GenAI's ability to rapidly generate questions, including multiple-choice questions (MCQs), from provided texts, doubts persist regarding its capability to create valid test questions due to its lack of exposure to specific module learning objectives, teaching materials, and students' language proficiency levels. The following chart illustrates an example of transferring reading skill constructs into multiple-choice question types.
3.2 Prompt refinement
While GenAI does have its limitations, by refining the prompts, exam developers can enhance the quality of generated items. Figure 1 shows how results can be improved by specifying question types.

Figure 1 sample questions generated by XIPU AI
Drawing from the author's experience, in addition to considering various question types, optimizing the performance of XIPU AI in generating multiple-choice questions (MCQs) involves paying attention to various nuances when refining the prompts. Firstly, it is crucial to paraphrase questions and options to reduce dependence on direct text quotes from texts (e.g. correct answer B in Figure 2 is a direct quote from text), thereby enhancing originality and minimizing reliance on memorization. Secondly, to bolster comprehension, questions can be structured in alignment with the sequence of information provided in the text rather than based solely on question types. Thirdly, correct answers need to be randomly assigned among the options to enhance unpredictability and effectively challenge readers. Finally, to enhance the plausibility of distractors, it is essential to ensure that questions cannot be answered solely through world knowledge. However, it is not advisable to overload a single prompt with all these specifics. Instead, employing multiple prompts with slight modifications each time, following the approach of progressive-hint prompting(Zheng et al., 2023) can generate more desired items.

Figure 2 sample question generated by XIPU AI with direct quotes in options
4. Conclusion
While GenAI serves as a valuable tool in aiding human reading assessment developers, its limitations highlight the necessity of human involvement in test development. This necessity arises primarily because test developers possess accurate knowledge of the language proficiency levels of the target students, module learning outcomes, and language assessment principles and constructs. This article draws from the author's experience with XIPU AI in developing reading tests in February 2024. It is important to note that some of the implications discussed might not be applicable to the current situation as AI technology continues to advance.
References
Brown, H. D. (2019). Language assessment : principles and classroom practices (P. Abeywickrama, Ed. Third edition ed.). Pearson Education.
Elkhatat, A. M. (2023). Evaluating the Authenticity of ChatGPT Responses: A Study on Text-Matching Capabilities. International Journal for Educational Integrity, 19(1). https://doi.org/https://doi.org/10.1007/s40979-023-00137-0
Oliver, R., Vanderford, S., & Grote, E. (2012). Evidence of English Language Proficiency and Academic Achievement of Non-English-Speaking Background Students. Higher Education Research & Development 31(4), 541-555. https://doi.org/https://doi.org/10.1080/07294360.2011.653958
Zheng, C., Liu, Z., Xie, E., Li, Z., & Li, Y. (2023). Progressive-Hint Prompting Improves Reasoning in Large Language Models. Retrieved 9 April from http://arxiv.org/abs/2304.09797

